应用场景
-
自动批量系统初始化(update,软件安装,时区设置,安全策略…)
-
自动化批量软件部署程序(LAMP/LNMP/Apache/LVS/Nginx)
-
管理应用程序(KVM,集群管理扩容,MySQL, DELLR720批量RAID)
-
日志分析处理日志(PV,UV, 200,!200, top 100/ grep, awk)
-
自动化备份恢复程序(MySQL完全/增量备份 + Crond)
-
自动化管理程序(批量远程修改密码,软件升级,配置更新)
-
自动化信息采集及监控程序(实时地收集系统/应用的状态信息:CPU,Mem,Disk,Net…)
-
配合zabbix信息采集(实时地收集系统/应用的状态信息:CPU,Mem,Disk,Net…)
-
自动化扩容(增加云主机->部署应用)
-
Zabbix监控CPU 80% + 调用Python的api 对AWS/EC2,ESC(增加 /删除云主机)+ Shell 脚本(业务上线)
程序的组成: 逻辑 + 数据
基本用法
一.常识
1.输入输出重定向
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
## 文件描述符:0,1,2 (对应:进程输入的文件,进程输入的文件,进程打开错误的文件)
0表示标准输入
1表示标准输出
2表示标准错误输出
## 输入输出重定向
# >, >>
> 默认为标准输出重定向,与 1> 相同
2>&1 把标准错误输出 重定向到 标准输出.
&>a.txt 把标准输出 和 标准错误输出 都重定向到文件中
# 2>, 2>> 错误输出最佳
# 2>>&1, &> 描述符为2的内容输入到描述符为1的内容(&> 是混合输出)
cat < /etc/hosts #(没加任何参数) 和不加<的机制不一样
cat < /etc/hosts > test/aaa.txt # 相当于copy文件内容
cat << EOF # 输入内容让cat来执行
cat <<EOF > file1 # 把一会输入的文件放到文件里面去
# 混合重定向 输出到/dev/null就是什么都不显示到终端
&> /dev/null
|
2.一些快捷键
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# ^R 搜索历史命令
# ![number] 执行历史命令中编号为`number`的命令
# ! string 找到最近一个以指定str开头的命令, 如:!da
# !! 上一个命令(在脚本中是不能手动按方向键的)
# !$ shell上一个命令的最后一个参数,
比如:ls aaa/bb /etc/passwd, 再执行: head !$, 看到是的passwd的内容
# ^D 退出
# ^A 跳到最前
# ^E 跳到最后
# ^K 向后删除
# ^U 向前 删除
# ^Y 撤销
# ^L
# ^S 锁屏暂停
# ^Q 恢复
|
3.在bash程序中嵌入一个python代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/bin/bash
# 第一行不是注释, 声明用哪个解释器 #!
ping -c1 114.114.114.114 && echo "114.114.114.114 is up" || echo "114.114.114.114 id down"
# <<-DOF:EOF是开始结束的标识(小横杠代表以下按tab,下面的py代码可以不tab缩进), EOF是不成文的规范
# 整个程序还是使用bash解释器,只不过是中间"请来一个人 - python"
# 如下:
/usr/bin/python3 <<-EOF
print("hello py")
EOF
echo "hello bash"
# 在bash中调用 python: expect
# 如果在python中使用bash, 要调用os.system('系统命令')
|
没有-的话,EOF作为结束符,前面不能有任何tab制表符。
有-的话,EOF作为结束符,前面可以有tab制表符,容错率更高一点。
4.配合figlet打印菜单:
1
2
3
4
5
6
7
8
9
10
11
|
#!/bin/bash
cat <<EOF
+-----------------------------------------------------+
| _ |
| _ __ ___ __ _ _ __ _ _ __ _| | |
| | '_ \` _ \ / _\` | '_ \| | ||/ _\` | | |
| | | | | | | (_| | | | | |_| |(_| | | |
| |_| |_| |_|\__,_|_||_|\__,_|\__,_|_| |
| |
+-----------------------------------------------------+
EOF
|
5.子shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#!/bin/bash
cd ~/Desktop
ls
# 这种做法,在终端执行完毕之后,当前目录还是没有变,因为他是在subshell (子shell中执行的)
# 要想使得subshell中的生效,就要使用`.` 或者 `source`
####### 执行脚本
./01.sh # 需要执行权限,在子shell中执行
bash 01.sh # 不需要执行权限,在子shell中执行
01.sh # 需要执行权限,在当前shell中执行
source 01.sh # 不需要执行权限,在当前shell中执行
|
6.shell元字符
通配符, 注意区分与正则中的元字符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#!/bin/bash
# * 任意多个字符
ls /etc/net*
# ? 任意一个字符
ls home/xp?
# [] 匹配括号内任意一个字符
[abc]
[a-z]
[^a-zA-Z0-9] # ^取反
l[io]ve
l[^a-z]ve
# () 命令在子shell中执行
(umask 077; touch test.txt) # 不影响创建文件的权限,当前shell的umask也没有改变
# ----- 回顾,子shell: .test.sh, source x.sh
# {} 集合
touch {1..9}
mkdir /home/{111,222}
mkdir -pv /home/{333,{aaa,bbb}, 444}
cp -rv /etc/{passwd, passwd.old} # 前面的相同的路径可以写在一块,后面不同的{}起来
cp -rv /etc/passwd{,.old} # 前面的相同的路径可以写在一块,后面不同的{}起来
# \ 转义符 让元字符回归本意
echo \*
echo \\
echo \ #后面紧跟回车,也就转义了回车
# -e 常规字符转变为特殊意义的:
echo -e "a\tb\nc"
|
7.前台后台
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#!/bin/bash
## & (关闭xshell,对应的任务也跟着停止)
sh test.sh &
## nohub
#任务放到后台,关闭标准输入,终端不再能够接收任何输入(标准输入),重定向标准输出和标准错误到nohup.out中
nohup sh test.sh
## 区分`nohub`与`&`:
1.& 是指在后台运行,但当用户推出(挂起)的时候,命令自动也跟着退出
2.nohub 退出终端之后该进程还是有的
## nohub与&合体
#将sh test.sh任务放到后台,但是依然可以使用标准输入,终端能够接收任何输入,重定向标准输出和标准错误到当前目录下的nohup.out文件,即使关闭xshell退出当前session依然继续运行。
nohup sh test.sh &
## screen
apt install screen # 安装
`sleep 100000` # 先执行,然后退出终端,
`screen -list` # 再次打开终端,指定这个命令,看到id
`screen -r yourID` # 然后输入这个命令,一切就回来了
## shell的会话作业机制
ctrl +c # 杀掉的是前台进程
# ^Z 放到后台, fg 调回来
kill %3 # 给当前终端作业号为3的发信号
## jobs 查看作业
## 管道 |
# tee 管道, -a 最佳
date | tee -a date.txt # 输出到文件,同时截流(能在终端直观地看到)
## 技巧: vim里面写脚本,可以按^Z暂停,到终端敲命令,让fg返回继续
|
8.命令排序
-
; 不具备逻辑排序 (前面执行完毕就执行后面的,不管前面成功失败与否)
-
&& 前面执行成功(即返回值$?为0)就执行后面的
-
|| 前面执行失败(即返回值$?为不为0)就执行后面的
相当于 if else
9.echo颜色输出
使用场景:给用户醒目提示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#!/bin/bash
# -e 才可以
# \e[1;3x
# \e[1;3x 前景色(30-37),m后面是文字
echo -e "\e[1;31mThis is a red"
echo -e "\e[1;33mThis is a yellow"
# 0m 恢复颜色
echo -e "\e[1;0m"
echo -e "no color"
## 常用: 前面变色之后, 后面紧跟:\e[0m 不变色(后面的内容就正常了)
echo -e "\e[1;31mThis is a red text. \e[0m"
echo -e "no color again"
## 背景色(40-47)
echo -e "\e[1;41mThis is a red text background coloe. \e[0m"
echo -e "\e[1;42mThis is a red text background coloe. \e[0m"
echo -e "\e[1;43mThis is a red text background coloe. \e[0m"
echo -e "\e[1;44mThis is a red text background coloe. \e[0m"
echo -e "\e[1;45mThis is a red text background coloe. \e[0m"
# printf 也是,不过是加了输出格式
|
10.切换用户
1
2
3
|
# 切换用户尽量加 -
su - xxx # 加横线, shell的环境也跟随改变 (login shell) ; 执行的是前四个: bashrc和profile
su xxx # 不加横线,当前环境还是当前的 () ; 执行的是两个bashrc文件
|
11.关于bash的文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
## 关于bash的文件:
# 系统级别 来到shell时候执行
/etc/profile
/etc/bashrc
# 用户级别 来到shell时候执行
~/.bashrc
~/.profile
# 离开shell时候执行
~/.bash_logout
~/.bash_history
# 修改用户的shell
usermod -s /bin/bash xps
# 下面两个
# login shell
# nologin shell
# /bin/bash
# /sbin/nologin
|
12.其他
1
2
3
4
5
6
7
8
|
# shift 使位置参数向左移动,默认移动1位,可以使用shift2
while [ $# -ne 0 ]
do
let sum+=$i
shift
# shift 2
done
echo "$sum"
|
二.变量
位置变量
1
2
3
4
5
6
7
8
9
10
11
|
脚本执行时,后面的第几个参数 $1 后面第一个参数 $2 $3 ${10}
## 比如下面的例子;
# bash test.sh 111 222 333
ping -c1 $1 &>/dev/null
if [ $? -eq 0 ] # 如果`上一条命令`返回值等于0(正常执行) -eq
then
echo "$1 is up"
else
echo "$1 is down"
fi
|
预定义变量
1
2
3
4
5
6
7
|
$0 # 脚本名
$* # 所有的参数
$@ # 所有的参数
$# # 参数的个数
$$ # 当前进程的PID echo $$
$! # 上一个`后台`进程的PID
$? # 上一个命令的返回值(0为成功)
|
ping 文件
1
2
3
4
5
|
# 如果用户没有加参数
if [ $# -eq 0 ];then
echo "usage: file `basename $0` need parmter"
exit
fi
|
如果是文件 -f
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# 第一个参数如果不是文件
if [ ! -f $1 ];then
echo "not a file"
exit
fi
##
# 第一个参数是文件,从中读取ip然后ping
for ip in `cat $1`
do
ping -c1 ip $>/dev/null
if [ $? -eq 0 ];then
echo "$ip is up"
else
echo "$ip is down"
fi
done
##
# basename 始终显示路径最后一个文件
# dirname 始终显示路径前面目录的名字
|
环境变量
export
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
## 在系统配置中用的多
# 例如:自己添加环境变量:到/etc/profile
PATH=$PATH:/new/bin
export PATH
# 然后sourcess
# 查看环境变量
echo $PATH
echo UID
echo $SHELL
echo $USER
echo $HISTORY #历史记录命令默认记录1000条
# 显示所有的环境变量:
env
# 取消环境变量:
unset 变量名
|
自定义变量
作用范围:当前shell中生效(a.sh或bash a.sh), 子shell中不行
1
2
3
4
5
6
7
|
## 转为环境变量 export (在一个脚本文件中export, 在另一个脚本中就可以获取了)
export ip1
## ps: 自己没必要定义环境变量
F1: 先 .test.sh 再echo $ip1
F2: 或者在一个脚本中引用加载另外一个脚本(./test.sh),后面就可以用了(没必要在每个文件中都定义一遍变量)
|
变量的赋值
1.显式赋值 (变量要以字母或者下划线开头,数字不可以开头)
1
2
3
4
5
|
## 常规赋值
# shell中没有数据类型,都是字符串
## 命令替换, 先把这个命令执行一遍再赋值: 反引号 ` `, $()
today = `date + %F`
|
2.read读取赋值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
## -p提示信息。-t等待时间。-n只要前面几个字符
# read -p "提示信息: " 变量名
# read -t 5 -p "提示信息: " 变量名
# read -n 2 变量名
# read 可以同时跟多个变量。空格隔开,直接一次性赋值
read -p "输入姓名,年龄,性别[e.g zhangsan 20 m]: " name age gender
echo "your name: $name, your age $age, your gender $gender"
### 注意事项:
"" # 弱引用(里面可以放变量$ip)
'' # 强引用(里面不能引用变量,会原样输出)
### 命令替换: `` 等价于 $(), 里面的命令会先执行
|
使用变量
变量赋值,等号两边不能有空格
1
|
ping -c1 $ip &>/dev/null && echo "$ip is up" || echo "$ip is down"
|
变量引用
1
2
3
|
## 引用
1. $变量
2. ${变量} # 大括号简单理解为:防止歧义
|
变量的运算
使用场景:内存使用, ping次数等 … …
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
## 1.整数运算 90%以上
# 方法1: expr + - \* / %
expr 1+2
expr $num1 + $num2
# 方法2: $(()) + - * / %
echo $(($num1+$num2))
echo $((num1+num2))
echo $((5-3*2))
echo $(((5-3)*2))
echo $(((2**3))
echo $(((1+2));echo $sum
# 方法3: $[] + - * / %
echo $[5+2]
echo $[5**2]
# 方法4: let 使用最多
let sum=2+3;echo $sum
let i++;echo $i
## 2.小数运算
echo "2*4"|bc
echo "2^4"|bc
echo "scale=2;6/4"|bc
awk 'BEGIN{print 1/2}'
echo "print 5.0/2"|python
|
变量的删除/替换
使用场景:让你输入值但是你没输入,我就给你一个默认值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
### 删除
url="www.baidu.com"
echo ${#url} # 从前往后,井号,输出长度, 最短匹配
echo ${url#www.} # 把前面部分删除
echo ${url#*baidu.} # 把前面部分删除 *
echo ${url##*.} # 从前往后,贪婪匹配,最长匹配
echo ${url%.} # 从后往前, 最短匹配
echo ${url%%.} # 从后往前,贪婪匹配
### 切片
echo ${url:0:5} #
echo ${url:5:5} # 从5开始,拿5个
echo ${url:5:}
### 变量内容的替换
url="www.baidu.com"
echo ${url/baidu/sina} # 百度换成新浪
echo ${url/n/N}
echo ${url//n/N} # 贪婪匹配
## ${变量名-新变量值}
# 替代(没赋值;如果变量之前有值即便是空值就不能替代)
unset var1
echo ${var1-aaa}
## ${变量名:-新变量值}
# 没赋值或者为空,就可以替代;如果变量之前有值就不能替代
### 拓展:
${变量名+新变量值}
${变量名:+新变量值}
${变量名=新变量值}
${变量名:=新变量值}
${变量名?新变量值}
${变量名:?新变量值}
#### 自增自减
# i++
# ++i
## 对变量值的影响: 没啥区别
## 对表达式值的影响: ++i 先自增再赋值, i++ 先赋值在自增
|
三.条件判断
if
shell中最核心的
1.文件测试 [操作符 + 文件或目录]
命令格式1:test
1
2
3
4
5
6
7
|
# 比如判断文件是否存在,如果存在就备份(概念版)
back_dir=/var/mysql_bak
if ! test -d $back_dir;then # 条件测试语句test, 如果不是目录或者这个目录不存在
mkdir -p $back_dir
fi
echo "开始备份..."
# 执行 bash -vx test.sh -vx可以看详细执行过程
|
命令格式2: [ -d /home ] 方括号取代了test(注意有空格)
1
2
3
4
5
6
|
# man test, 帮助文档相同。 前半边是命令[, 后半边]只是一个符号
back_dir=/var/mysql_bak
if [ ! -d $back_dir ];then # 如果不是目录或者这个目录不存在
mkdir -p $back_dir
fi
echo "开始备份..."
|
命令格式3: [[ -d /home ]]
1
2
3
4
5
6
7
8
9
10
11
12
|
# [ -e dir|file ]
-d 是否是目录
-f 是否为文件
-r `当前用户`是否对该文件有读权限
-w
-l 是否是链接
-b 是否为设备文件
-c 是否为字符设备
#
[ ! -d /cc ] && mkdir /cc # 当前不是一个目录或者目录如果不存在,就创建
[ -d /ccc ] || mkdir /ccc # 当前是一个目录或者目录如果存在,就不创建
|
2.数值比较
1
2
3
4
5
6
|
# [ 1 -gt 10 ] 大于
-lt 小于
-eq 等于
-ne 不等于
-ge >=
-le <=
|
1
2
3
4
5
6
|
#安装软件,先判断是否为root用户
if [ $UID -ne 0 ];then # $UID不等于0,代表不是root用户(数值比较)
echo "你没有权限!"
exit
fi
apt install apache2
|
例子:用户输入(read)用户名,创建这个用户
1
2
3
4
5
6
7
8
9
10
|
read -p "input the user name: " user
id $user &>/dev/null
if [ $? -eq 0 ];then # 如果用户存在
echo "user $user already exists"
else
useradd $user
if [ $? -eq 0 ];then
echo "$user is created."
fi
fi
|
例子2: 如果磁盘是使用量超过90%, 就报警
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# grep'/$' 是提取根分区, $(NF) 是倒数第一列, awk是以什么分割
dick_use=`df -Th |grep'/$'|awk '{print $(NF-1)}'|awk -F"%" '{print $1}'`
mail_user=alice
warn_file=/tmp/disk_warn.txt
if [ $dick_use -gt 90 ];then
echo "`date +%F:%H` disk: ${dick_use}%" >warn_file
fi
if [ -f $disk_warn ];then # 将报错文件发送给邮件用户
mail -s "disk warning..." $mail_user < $dick_use # |mail -s 邮件主题
rm -rf $disk_warn
fi
# 可以用crontab,定时执行(crontab -e会把所有的任务清除)
# 换行是 \
|
3.字符串比较
1
2
3
4
5
6
7
8
9
|
=
==
!=
[ -n "hhh" ] # 长度不是0
[ -z "$user" ] # 长度为0 (变量为空/未定义 => 都是0)
-a # 并且 [1 -lt 1 -a 5 -gt 10]
-r # 或者
&&
||
|
1
2
3
4
5
|
if [ $USER != 'root' ];then # $USER不等于root(字符串比较)
echo "你没有权限!"
exit
fi
apt install apache2
|
例子:批量创建用户
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
#尽量使用双引号引起来
#[ "$USER" = "root" ]
#!/bin/bash
##################################
#脚本规范 #
#useradd #
#V1.0 by xps 01/03/2020 #
##################################
read -p "Please input number: " num
# read -p "Please input 前缀: " prefix
while true
do
# 对用户输入进行过滤(数字) ^[0-9]+$ 正则 =~ (模式串不能带双引号)
#if [[ ! "$num" =~ ^[0-9]+$ || "$num" =~ ^0+$ ]];then # []单个方括号不支持正则,用[[ 变量 =~ 模式 ]]
if [[ "$num" =~ ^[0-9]+$ ]];then
break
else
read -p "不是数字,Please input number again: " num
fi
done
read -p "Please input 前缀: " prefix
while true
do
if [ -n "$prefix" ];then # 如果长度为非0
break
else
read -p "Please input 前缀: " prefix
fi
done
# man seq 打印序列: seq 1 2 10 (区间,步长)
for i in `sql $num`
do
user=$prefix$i
useradd $user
echo "123" |passwd --stdin $user # --stdin 前面输出的当做标准输入
if [ $? -eq 0 ];then
echo "$user is created."
fi
done
# declare 可以定义数据类型。但是一般不用,因为都是字符串
## 语法不难,主要是对Linux系统以及命令的熟悉。
|
1
2
3
4
5
6
7
8
9
|
# if后门紧跟的不一定是方括号,只要是能返回true/false的就行
if [[ condition ]]; then
#statements
elif [[ condition ]]; then
#statements
elif [[ condition ]]; then
#statements
fi
|
switch
语法结构
1
2
3
4
5
6
7
8
9
10
11
12
13
|
case 变量 in
模式1) # 都是字符串, 可以用通配符 (尽量使用双引号)
命令序列1
;;
模式2)
命令序列2
;;
模式3)
命令序列3
;;
*)
无匹配后命令序列
esac
|
例子1:删除用户
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
read -p "请输入要删除的用户名: " user
id $user &>/dev/null
if [ &? -ne 0 ];then
echo "no suc user: $user"
exit 1 # 返回1(意思是错误退出)
fi
read -p "你确定要删除用户: $user 吗 ?[y/n]: " action
case "$action" in
y|Y|yes|YES)
userdel -r $user
echo "deleted user: $user success!"
;;
*)
echo "error"
esac
|
例子2: 判断一个东西是不是命令
1
2
3
4
5
6
7
8
9
10
11
|
# command -v xxx
# echo $? 返回为0就是
command -v ls
cmd1=/bin/date
if command -v $cmd1 &>/dev/null;then
# 神马都不做: 只加一个冒号
:
else
echo "$cmd1 是一个命令"
fi
|
例子3:通过登录堡垒机/跳板机 jumpserver ,然后登录内网的服务器 (简易版)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
# 1.先登录到跳板机(普通账号)
# 2.跳板机登录到other server()
# 登录两次,有点麻烦
# 例子: 先登录到跳板机,再通过选项选择要登录到哪台服务器(1.密码认证 2.秘钥认证:以用户xps身份做 ssh-keygen, ssh-copy-id web1)
# 以xps身份登录上来, 秘钥登录服务器
# 脚本放到/home/xps/jumpserver.sh, 放到bashrc,登录这台机器就执行,并且禁止用户(^C)退出
trap "" HUP INT OUIT TSTP # 捕捉键盘信号,然后啥也不做(^C也退出不了) ,让他登录跳板机不能干别的
web1=192.168.0.111
web2=192.168.0.112
web3=192.168.0.113
cat <<-EOF
+---------------------------+
| 1. web1 |
| 2. web2 |
| 3. mysql1 |
+---------------------------+
EOF
echo -en "\e[1;32minput number: \e[0m" # 显示颜色, -n不换行
read num
while true
do
case "$num" in
1)
ssh xps@$web1
;;
2)
ssh xps@$web2
;;
3)
ssh xps@$mysql1
;;
"")
# 用户啥也没输入
true
*)
echo "error"
esac
done
## 生产环境
#1. 业务服务器不允许直接连接,允许通过跳板机连接
#2. 业务服务器不允许root用户直接登录
### 复杂版jumpserver(对用户行为进行行为/记录) ---> 使用Python脚本
|
例子4:实现系统管理工具箱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#!/bin/bash
## 实现系统管理工具箱
# 定义一个函数
menu{
cat <<-EOF
##########################################
# h. help #
# f. disk partion #
# d. filesystem mount #
# m. memory #
# u. system load #
# q .exit #
##########################################
EOF
}
menu
while true
do
read -p "Please input[h for help]: " action
case "$action" in
h) clear; menu;;
f) fdisk -l;;
d) df -Th;;
m) free -m;;
u) uptime;;
q) break;;
"") ;;
*) echo "error";;
esac
done
echo "finish..."
|
各种符号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#!/bin/bash
() # 在子shell中执行
((1<2)) # C语言风格的比较
$(date) # touch $(date +%F)_file.txt 先执行里面的命令再执行外面的
$(()) # 运算
{} # 集合{1..5}
${} # 变量的引用
[] # 条件测试 逻辑符号 [ a -a b ]
[[]] # 升级版的。 支持正则匹配 [[ =~ ]], 逻辑符号 [[ a && b ]]
$[] # 整数运算
####### 执行脚本
./01.sh # 需要执行权限,在子shell中执行
bash 01.sh # 不需要执行权限,在子shell中执行
01.sh # 需要执行权限,在当前shell中执行
source 01.sh # 不需要执行权限,在当前shell中执行
###### 调试脚本
sh -n 02.sh # 仅调试syntax error
sh -vx 02.sh # 仅调试的方式执行,查询整个执行过程
|
四.循环
for循环
处理固定循环的时候,for有优势
形式
1
2
3
4
|
for 变量名 [ in 列表 ]
do
循环体
done
|
拓展: 查看脚本运行时间: time ./a.sh
例子1: for循环ping机器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 重定向
>ip.txt
# {2..254} 集合, 另一个序列: seq `2 254`
for i in {2..254}
do
{
$ip = 192.168.111.$i
ping -c1 -W1 $ip &>/dev/null # -W等待多少时间
if [ $? -eq 0 ]; then
echo "$ip" | tee -a ping.txt
fi
}& # 用大括号和&, 把整个循环【放到后台】
done
wait # 等待前面的所有【后台】进程结束,再执行后面的
echo "finish !"
|
例子2:从文件中读取主机,然后ping
1
2
3
4
5
6
7
8
9
10
11
12
|
# {2..254} 集合, 另一个序列: seq `2 254`
for ip in `cat ips.txt`
do
ping -c1 -W1 $ip &>/dev/null # -W等待多少时间
if [ $? -eq 0 ]; then
echo "$ip is up!"
else
echo "$ip is down!"
fi
done
wait # 等待前面的所有【后台】进程结束,再执行后门的
echo "finish !"
|
例子3:批量创建账号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
while :
do
read -p "input your prefix & passwd & number : " prefix passwd number
printf "user information:
---------------------------
username: $passwd
prefix: $prefix
number: $number
---------------------------
"
read -p "Are you sure?[y/n]" action
if [ "$action" = "y" ];then
break
fi
done
echo "continue ..."
# 然后是接下来的功能
for i in `seq -w $number`
do
user = $prefix%i
id $user &>/dv/null
if [ $? -eq ];then
echo "user $user already exists"
else
useradd $user
echo "$passwd" | --stdin $user # 将密码作为标准输入
if [ $? -eq 0 ];then
echo "$user is created."
fi
fi
done
# bash -n .sh 检查脚本错误
|
例子4:批量创建账号(从文件中)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
passwd = 123
# 必须要输入文件
if [ $# -eq 0 ];then
echo "usage: `basename $0` file"
exit
fi
# 判断输入的是否是文件
if [ ! -f $1 ];then
echo "error file"
exit 2
fi
# 开始(两列 -- > 把密码和用户名分开)
# 应该:重新定义分隔符
# IFS内部字段分隔符,比如下面的回车
# IFS = $'\n'
for line in `cat $1` # 位置变量 , for对空行不感冒
do
# 长度为0就跳过
if $[ ${#line} -eq 0 ];then
echo "Nothing to do."
continue
fi
user = `echo "$line" |awk 'print &1'`
pass = `echo "$line" |awk 'print &2'`
id $user &>/dv/null
if [ $? -eq ];then
echo "user $user already exists"
else
useradd $user
echo "$pass" | --stdin $user &>/dev/null # 将密码作为标准输入
if [ $? -eq 0 ];then
echo "$user is created."
fi
fi
done
|
例子5:批量修改密码(剩下的功能自己完善)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 目前:通的放一个文件,不通的放一个文件
for ip in $(cat ip.txt)
do
{
ping -c1 -W1 $ip &>/dev/null
if [ $? -eq 0 ];then
ssh $ip echo "123" |passwd --stdin $user # 采用的公钥认证
if [ $? -eq 0 ];then
echo "$ip" >>success_`date + %F`.txt
else
echo "$ip" >>failed_`date + %F`.txt
fi
else
echo "$ip" >>failed_`date + %F`.txt
fi
}&
done
wait
echo "end!"
|
例子6:批量修改主机ssh设置
1
|
ssh $ip "sed -ri '/~#UseDNS/cUseDNS0 no' /etc/ssd/sshd_config" # 搜索并替换(c)
|
while循环
逐行读取文件的时候,while有优势
不用像for循环那样担心每一行的空格空行
所以:读取一个文件中逐行处理,while比for好用
例子1:创建用户
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# 以后,读取一个文件中逐行处理,while比for好用
while read line:
do
# 判断用户数是否输入参数
if [ ${#line} -eq 0 ];then
continue
fi
user = `echo $line|awk '{printf $1}'`
pass = `echo $line|awk '{printf $2}'`
id $user &>/dev/null
if [ $? -eq 0 ];then
echo "user $user already exists"
else
useradd $user
echo "$pass" | --stdin $user &>/dev/null # 将密码作为标准输入
if [ $? -eq 0 ];then
echo "$user is created."
fi
fi
done < $1 # 可以换成位置变量, 从文件里面读取用户名(read不用-p了)
# done < user.tx #
|
例子2:while实现连接测试
1
2
3
4
5
6
|
# 只要ping通就一直ping(【条件为true时候一直执行循环】)
ip=192.168.0.5
while ping -c1 -W1 $ip &>/dev/null; do
sleep 1
done
echo "$ip is down!"
|
例子3:until 实现连接测试
1
2
3
4
5
|
ip=192.168.0.5
until ping -c1 -W1 $ip &>/dev/null; do
sleep 1
done
echo "$ip is up!"
|
- while 适合写主机下线
- until 适合写主机上线
until循环
形式
1
2
3
4
5
|
# 当条件测试为false时候执行循环体
until 条件测试
do
循环体
done
|
例子1:until实现数值运算
1
2
3
4
5
6
7
|
# i=1
until [ $i -gt 100 ] # >100
do
let sum+=$i
let i++
done
echo "sum: $sum"
|
例子2:while实现数值运算
1
2
3
4
5
6
7
|
#数值运算:let
i=1
while [ $i -le 100 ] # <=100
do
let sum+=$i
done
echo "sum: $sum"
|
并发
并发 —> 多进程
之前写的传统并发的方式,多进程(返回是时间是乱序的)
**缺点:**有些并发数量太多,会报错
格式:
1
2
3
4
5
6
|
...
{
...
}&
wait
...
|
比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
for i in {1..254}
do
{
ip=192.168.0.$i
ping -c1 -W1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo "$ip is up."
else
echo "$ip is down."
fi
}&
done
wait
echo "执行结束..."
|
控制并发的数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
### 1). FD(File Descriptors)文件描述符 或 文件句柄
# 进程使用文件描述符来管理打开的文件(位置: /proc/进程id/fd/)
# $$是当前进程
exec 6<> /file1 # 1.手动指定描述符来 打开文件
echo "111" >> /proc/$$/fd/6 # 2.写入到了file1
# 3.删除file1
# 4.然后查看文件句柄:
ll /proc/$$/fd
# 会发现6显示删除状态
## 5.把6这个文件拷贝出来变成file1,就又回来了(如果文件句柄没有删除或关闭。就算原文件被删除了,句柄依然在)
ls of # 6.列出打开的文件
exec 6<&- # 7.释放文件的句柄
### 2). 管道
## 匿名管道(一个终端内使用) |
## 跨终端使用 mkfifo
mkfifo /tmp/fifo1 # 创建
ll /dev > /tmp/fifo1 # 把dev重定向到管道中,另一个终端就可以用了
# 另一个终端使用:
grep 'sda' /tmp/fifo1
|
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
thread=5
tmp_fifofile=/tmp/$$.fifo
mkfifo $tmp_fifofile
exec 8<> $tmp_fifofile
rm $tmp_fifofile
for i in `seq $thread`
do
echo >&8 # 操作的是文件描述符()
done
for i in {1..254}
do
read -u 8 # -u 是读取文件描述符内容(逐行)
{
ip=192.168.0.$i
ping -c1 -W1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo "$ip is up."
else
echo "$ip is down."
fi
echo >&8 # 有借有还(借一个还一个,不能让文件描述符里面空)
}&
done
wait
echo "执行结束. .."
# 执行结果是5个5个出来的(因为定义的进程是5个)
|
expect
expect —-> 不是shell,是一个新的语言
解决交互的繁琐操作
安装:apt install expect
expect实现批量远程命令执行
1
2
3
4
|
# 如果for while,需要一步步的交互(比较麻烦),但是可以使用公钥认证(ssh-keygen,ssh-copy-id)
#第一步,实现了公钥认证
# ps:如果登录的新的机器与之前的指纹不一样,先删除本地保存的信息
# expect打前站,先把公钥推过去,后面再用别的实现
|
ssh初级例子1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#!/usr/bin/expect
set ip 192.168.0.1
set user root
set passwd 123456
set timeout 5
spawn ssh $user@$ip
expect { #就是把接下来要出现的字符串等提前写好
"yes/no" { send "yes\r"; exp_continue } # 当出现什么,怎么处理(没出现就继续)
"password:" { send "$passwd\r" };
}
interact #交互停在对方那边不退出来
# 执行脚本: expect test.sh
|
ssh初级例子2(升级版):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#!/usr/bin/expect
set ip [lindex $argv 0] # 第一个位置参数(与shell的不通)
set user [lindex $argv 1]
set passwd 123456
set timeout 5
spawn ssh $user@$ip
expect { #就是把接下来要出现的字符串等提前写好
"yes/no" { send "yes\r"; exp_continue } # 当出现什么,怎么处理(没出现就继续)
"password:" { send "$passwd\r" };
}
#interact # 交互停在对方那边不退出来
# 干点别的事情
expect "#" # 不用大括号也可以
#send "useradd xps\r"
send "pwd\r"
send "exit\r"
expect eof # 结束expect
|
例子3:scp传递文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
######## 升级版
#!/usr/bin/expect
set ip [lindex $argv 0] # 第一个位置参数(与shell的不通)
set user [lindex $argv 1]
set passwd 123456
set timeout 5
spawn scp -r /etc/xxx $user@$ip:/tmp
expect { #就是把接下来要出现的字符串等提前写好
"yes/no" { send "yes\r"; exp_continue } # 当出现什么,怎么处理(没出现就继续)
"password:" { send "$passwd\r" };
}
expect eof # 结束expect
|
例子4: 推公钥
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
# shell与expect一起用
#!/bin/bash
>ip.txt
passwd=123
#测试expect有没有装(以centos为例)
rpm -q expect &/dev/null
if [ $? -ne 0 ];then
yum -y install expect
fi
# 判断是否有公钥
if [ ! -f ~/.ssh/id_rsa ];then
ssh-keygen -P "123" -f ~/.ssh/id_rsa # 指定公钥的密码和位置
fi
for i in {2..254}
do
{
ip=192.168.0.$i
pign -c1 -W1 $ip &/dev/null
if [ $? -eq 0 ];then
echo "$ip" >> ip.txt
# 开始expect
/usr/bin/expect <<-EOF
set timeout 10
spawn ssh-copy-id $ip # 推送公钥。 前面必须都是tab,不能有空格(:set list 查看是tab还是空格)
expect {
"yse/no" { send "yes\r"; exp_continue }
"password:" { send "$passwd\r" }
}
expect eof
EOF
fi
}&
done
wait
echo "finish..."
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 上一个例子, 已经实现了公钥认证,后面的操作就可以使用shell了,基本不用expect了
# 重启之后查看机器的ip,直接用get_ip.sh脚本(就不用了一个一个去看了)
#!/bin/bash
>ping.txt
# {2..254} 集合, 另一个序列: seq `2 254`
for i in {2..254}
do
{
$ip = 192.168.111.$i
ping -c1 -W1 $ip &>/dev/null
if [ $? -eq 0 ]; then
echo "$ip" | tee -a ping.txt
fi
}& 】
done
wait
echo "finish !!!"
|
五.数组
没有多维数组这个概念
定义
1.普通数组
1
2
3
4
5
6
7
|
# 普通数组:只能使用整数作为数组索引
books=(linux shell awk docker)
books=(linux shell awk [20]=docker) # 索引20为docker
# 从文件赋值
books2=(`cat /etc/passwd`)
books=(`ls /etc/`)
# 中间值可以跳过
|
2.关联数组
1
2
3
|
# 关联数组:可以使用字符串作为数组索引(相当于字典)
declare -A info # 先声明是关联数组
info ([name]=xps [sex]=male [age]=20 [skill]=security) # 赋值
|
使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
echo ${books[3]}
echo ${info[name]}
# 查看所有的数组
declare -a
# 查看所有的关联数组
declare -A
# 获取数组元素的索引号
echo ${info[@:1]} # 从数组下标1开始
echo ${info[@:1:2]} # 从数组下标1开始,访问两个元素
# 获取所有的索引key
echo ${!info[@]}
# 统计元素个数
echo ${#info[@]}
# 数组中所有元数(等同于: ${info[*]} )
echo ${info[@]}
|
遍历
1.按照个数遍历
2.按照索引遍历
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#while方式
i=0
while read line
do
hosts[++i]=$line #hosts是个数组
done </etc/hosts
for j in ${!hosts[@]}
do
echo "$i: ${hosts[i]}"
done
########################################################################3
# for方式 不是以换行分割(按照空格,tab等分割)
OLD_IFS=$IFS
IFS=$'\n' # 解决
for i in ${!hosts[@]}
do
echo "$i: ${hosts[i]}"
done
for j in ${!hosts[@]}
do
echo "$i: ${hosts[i]}"
done
IFS=$OLD_IFS # 不是全文都要,如果后门想用回车作为分隔符号
|
实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
#!/bin/bash
## 1. 性别次数统计
## 其实用awk一行搞定
awk '{print $2}' sex.txt |sort |uniq -c
## 这里还是先学基础的(`把要统计的对象作为数组的索引` ,首先是关联数组)
#!/bin/bash
declare -A sex
while read line
do
# 里面的第二列(m/f)
type=`echo $line |awk '{print $2}'`
let sex[$type]++ # sex[m]++ 性别的数量增加
done < sex.txt
# 遍历(通过索引)
for i in ${!sex[@]} # 获取所有的索引key
do
echo "$i: ${sex[$i]}" #变量尽量加$
done
### 2. 统计不同类型shell的数量
# /etc/passwd中
#!/bin/bash
declare -A shells # 先定义关联数组
while read line
do
# 里面的第二列
type=`echo $line |awk -F":" '{print $7}'` #按照冒号分割 {print $NF}最后一列
let shells[$type]++ # sex[m]++ 性别的数量增加
done < /etc/passwd
#输出
for i in ${!shells[@]}
do
echo "$i: ${shells[$i]}" # /bin/bash : 5
done
### 这是awk的强项
awk -F":" '{print $NF}' /etc/passwd |sort |uniq -c
## 3. 统计tcp连接状态数量
#ss -an |grep 80
#!/bin/bash
while :
do
unset status # 取消, 重新声明
declare -A status # 先定义关联数组
type=`ss -an |grep :80 |aek '{print $2}'` # 要统计的(是一个arr)
for i in $type
do
let status[$i]++
done
#输出
for i in ${!status[@]}
do
echo "$i: ${status[$i]}" # SYN-SENT: 5
done
sleep 1
clear
done
# 思想: 把要统计的对象最为索引,一直累加
## 拓展:
## 一.如果想一直看
# 1. watch -n2 test.sh # 每几秒看一次
# 2. 脚本里面while循环(更麻烦)
## 二.vim部分复制粘贴:
# ^V 块选择,然后按y复制, 最后找到地方p粘贴
|
六.函数
定义
1
2
3
4
5
6
7
8
9
|
# F1:
函数名(){
功能
}
# F2:
funcion 函数名{
功能
}
|
调用
调用1
1
2
3
4
5
6
7
8
9
10
11
|
#例子:阶乘
#!/bin/env bash
factorial(){
fat=1
for((i=1;i<=50;i++))
do
fac=$[$fac*$i]
done
echo "5的阶乘:$fac"
}
factorial # 调用
|
调用2
1
2
3
4
5
6
7
8
9
10
11
|
#!/bin/env bash
factorial(){
fat=1
for((i=1;i<=$num;i++))
do
fac=$[$fac*$i]
done
echo "$num的阶乘:$fac"
}
num=5 # 调用之前先定义变量
factorial
|
调用3
1
2
3
4
5
6
7
8
9
10
11
|
#!/bin/env bash
factorial(){
fat=1
for i in `seq $1`
do
let fac*=$i
done
echo "$1的阶乘:$fac"
}
factorial $1 # 位置变量,调用
|
调用4
1
2
|
# 如果函数再另一个文件里面,先执行一下,后面再调用
./f1.sh
|
返回值
1
2
3
4
5
6
7
8
9
10
|
#!/bin/env bash
fun2(){
read -p "enter a number:" num
let 2*$num
return $[2*$num]
}
fun2
echo "funcion return value: %?" # 上一个命令的返回值(函数值最后一条命令的返回的状态码)
echo "funcion return: $?" # 函数的返回值(也可以自定义,但是默认shell返回码,最大不能超过255)
|
如果想返回字符串等: 函数的输出
1
2
3
4
5
6
7
8
|
#!/bin/env bash
fun2(){
read -p "enter a number:" num
echo $[2*$num] # echo
}
result=`fun2` # 使用函数的输出
echo "return_out value: $result"
|
参数的传递
1.位置参数
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#!/bin/env bash
if [ $# -ne 3 ];then # 如果参数不是三个
echo "Usage: `basename $0`par1 par2 par3 "
exit
fi
function parm_func(){
echo "$(($1 * $2 * s3))"
}
result=`parm_func $1 $2 $3` # 分清:程序的位置参数,函数的位置参数
echo "result is: $result"
|
2.数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#!/bin/env bash
num=(1,2,3,4,5)
#echo "${num[@]}" #打印所有元素
arr_parm() {
local fa=1 ## 局部变量,只在函数内部生效
for i in "$@"
#for i in $*
do
let fa*=$i
done
echo "$fa"
}
#arr_parm ${num[@]}
arr_parm ${num[*]} # 数组所有 元素值
# 拓展:
# for i in $* # 所有参数
# for i
|
传数组到函数中 –> 运算 –> 输出数组形式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/bin/env bash
num=(1,2,3,4,5)
array() {
#echo "所有参数: $*"
local new_arr=(`echo $*`)
#local new_arr=($*)
local i
for ((i=0;i<$#;i++))
do
out_arr[$i]=$[ ${[$i]}*5 ]
done
echo "${out_arr[*]}"
}
result=`array${num[*]}`
echo ${result[*]}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#!/bin/env bash
num=(1,2,3,4,5)
array() {
local i
local new_arr=()
for i in $*
do
new_arr[j++]=$[$i*5]
done
echo "${new_arr[*]}"
}
result=`array${num[*]}`
echo ${result[*]}
# 函数接收位置参数 $1 $2 $3
# 函数接收数组参数 $* 或 $@
#函数将接收到的所有参数赋值给数组 new_arr=($*)
|
七.正则
大多数程序中,正则表达式被放在两个正斜杠之间, 比如:/L[oO]ve/
入门小例子
1
2
3
4
5
6
7
8
9
|
# 简单实例(不严谨的例子,我们写shell脚本没必要写那么复杂,我们的脚本是给自己用的多)
匹配数字: ^[0-9]+$
匹配Email: [a-z0-9_]+@[a-z0-9]+\.
匹配IP: [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
或者 [[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]{1,3}
#
egrep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' /etc/sysconfig/network-scripts/ifcfg-eth0
|
正则 元字符
注意和shell的元字符是不太一样的
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 由执行模式匹配的操作的程序来解析,比如vi,grep,sed,awk,python
# 只要不是shell,就是正则的元字符
rm -rf *.pdf # shell中的*, 匹配任意
grep 'c*' /etc/passwd # c出现0次或者多次
egrep 'c+' /etc/passwd # +要使用egrep或反斜杠
vim中替换: `:%s/\<[tT]om\>/TOM/g` # 尖括号括起来的是单词
## 例子:
grep "sh$" /etc/passwd
grep "ro*t" /etc/passwd
grep "^[rot]" /etc/passwd # 以r或o或t开头的
|
1.基本元字符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
^ 行首定位符 ^love
$ 行位定位符 love$
. 匹配单个字符 l..e
* 匹配前导符0到多次 ab*love
.* 任意多个字符
[] 匹配指定范围内的一个字符 [lL]ove
[-] 匹配指定范围内的一个字符 [a-z0-9]ove
[^] 匹配不再指定组内的一个字符 [^a-z0-9]ove
\ 用来转义元字符 love\.
\< 词首定位符 \<love
\> 词尾定位符 love\>
\(..\) 匹配稍后使用的字符的标签 :%s/172.16.130.1/172.16.130.5/
:%s/\(172.16.130.\)1/\15/
:%s/\(172.\)\(16.\)\(130.\)1/\1\2\35/
:3,9s/\(.*\)/#\1/ # 把第3-9行整行注释掉
# 大括号每一半前面要加斜线记得
x\{m\} 字符x重复出现m次 o\{5\}
x\{m,\} 字符x重复出现m次以上 o\{5,\}
x\{m,n\} 字符x重复出现m次 o\{5,10\}
|
2.拓展正则表达式元字符
1
2
3
4
5
6
7
8
9
|
+ 匹配一个或多个前导字符 [a-z]+ove
? 匹配零个或一个前导字符 lo?ve # o出现0次或1次 ss -an |egrep ':80:22\>'
a|b 匹配a或b love|hate
() 组 字符 loveablle|rs love(able|rs)ov+ (ov)+ ov+ # 里面内容作为一个整体
(..)(..)\1\2 标签匹配字符 (love)able\1er # 不带斜线
x{m} 字符x重复出现m次 o{5}
x{m,} 字符x重复至少m次 o{5,}
x{m,n} 字符x重复m到n次 o{5,10}
|
3.POSIX字符类 (类似于shell中环境变量,已经定义好的)
1
2
3
4
5
6
7
8
|
[:alnum:] 字母与数字字符 [[:alnum:]]+ # 外面的方括号是包里面的
[:alpha:] 字母字符(包括大小写字母) [[:alpha:]]{4}
[:blank:] 空格与制表符 [[:blank:]]*
[:digit:] 数字 [[:digit:]]?
[:lower:] 小写字母 [[:lower:]]{5,}
[:upper:] 大写字母 [[:upper:]]+
[:punct:] 标点符号 [[:punct:]]
[:space:] 包括换行符、回撤等在内的所有空白 [[:space:]]+
|
带括号与不带括号:
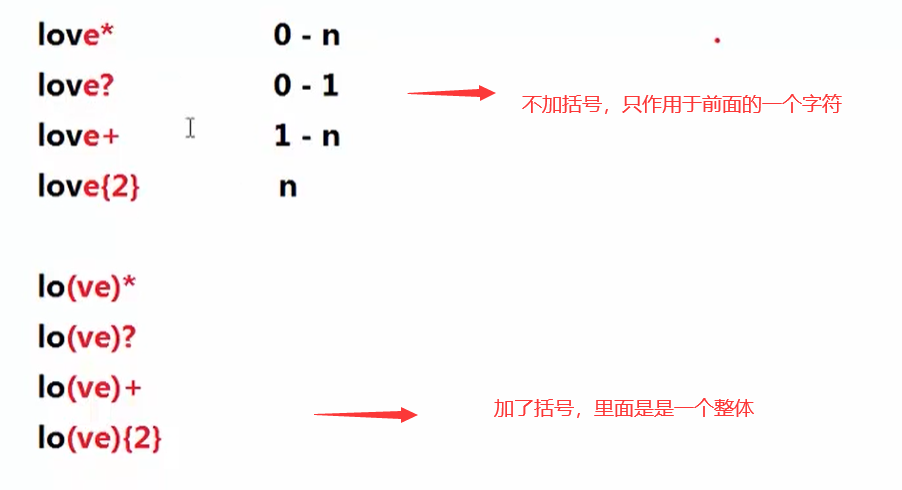
正则匹配实例:vim中查找替换
1
2
3
4
5
6
7
|
# 空行:
/^$/
/^[\t]*$/
# 注释行:
/^#/
/^[\t]*#/
|
grep
- grep 文件中查找指定的正则表达式
- egrep 拓展的egrep,支持更多的正则表达式元字符
- fgrep 固定grep(fixed grep),有时也被称作快速(fast grep), 它按字面解释所有的字符
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#过滤(尽量加引号)
grep [选项] PATTERN 文件 文件 文件
grep -q "root" /etc/passwd : echo $?
# 返回值:
# 0 找到
# 1 没找到
# 2 找不到指定文件
# grep的输入可以来自:文件、标准输入、管道
ss -an |grep ":22$"
ll |grep '^d' # 找出目录
|
使用的元字符
1
2
3
4
5
6
7
8
9
10
11
12
|
grep: 使用基本元字符集 ^, $, ., *, [], [^], \<\>, \(\), \{\}, \+,
egrep: 使用扩展元字符集 ?, +, {}, |, ()
#
Note: grep也可以使用扩展元字符集,仅需再这些元字符前置一个反斜线(尖号不行)
\w 所有字母与数字,称之为字符,即 [a-zA-Z0-9]
\W 与上面相反,非字符 [^a-zA-Z0-9]
\b 词边界
# grep -E 或 egrep
|
grep选项
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
-v 取反,只显示不匹配的
-i 忽略大小写
-l 只列出匹配行所在的文件名(哪些文件里面有这些匹配)
-n 再每一行前面加上他所在文件中的相对行号
-c 显示成功匹配的行数
-s 禁止显示文件不存在或文件不可读的错误信息
-q 静默
--color 颜色
-R, -r 递归针对目录
-o 只显示匹配的内容
-B 前几行 grep -C2 'root' /etc/passwd
-A 后几行
-C 上下几行
nmap --help |grep '\-u' # 查看帮助文档里的-u
|
八.sed
sed: 流编辑器,在线的、非交互式的编辑器(而vi是交互式的)
sed工作流程
文本文件 -> sed的模式空间(缓冲区) –> 输出
命令格式
1
2
|
#sed [options] 'cmd' file(s)
sed [options] -f scriptfile file(s)
|
sed不管是够找到指定的模式,他的退出状态都是0。 只有当命令语法存在错误时候,才是非0
可以在命令行,也可以在脚本里面使用
1
2
3
|
sed 'd' /etc/test # d 删除
sed '4d' /etc/test # 4d 删除第四行
# i 修改文件(不是输出到屏幕上)
|
支持正则表达式
支持的元字符
1
2
|
# 基本元字符集: ^, $, ., *, [], [^], \<\>, \(\), \{\}
# 扩展元字符集: ?, +, {}, |, ()
|
使用扩展元字符的方式
1
2
3
4
|
sed --help|grep '\-r'
#
\+
sed -r
|
基本用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
sed -r '' /etc/test # '' 没任何动作
sed -r 'd' /etc/test
sed -r 'p' /etc/test # p 打印
sed -r -n 'p' /etc/test
sed -r -n '/root/p' /etc/test # -n 静默方式
# 上面四种不建议用(打印这种事情用不着sed,有别的打印就行)
### 下面的功能才重点学
sed -r 's/root/xps' /etc/test # 所有行查找替换,root换成大小写(只替换一次)
sed -r 's/root/xps/g' /etc/test # g 全局
sed -r 's/root/xps/gi' /etc/test # i 忽略大小写
sed -r '/root/d' /etc/test # 没有s就是查找, 查找带root的行,然后删除
sed -r '\#root#d' /etc/test # 查找:可以使用#等符号-->不一定要斜线,但是前面要加\转义;查找替换:不用转义
|
地址(定址)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#!/bin/bash
# 用于决定对哪些行进行编辑。地址形式可以是数字、正则或二者的结合(如果没有指定,sed将处理输入文件中的所有行)
sed -r 'd' /etc/test
sed -r '3d' /etc/test
sed -r '1,3d' /etc/test
sed -r '/root/d' /etc/test # 删除root的行
sed -r 'root/,5d' /etc/test # 从root行开始,到第5行删除
sed -r 's/root/xps/g' /etc/test # 替换
sed -r '/^adm/,20d' /etc/test # 从adm开头的那一行,删除到第20行
sed -r '/^adm/,+20d' /etc/test # 从adm开头的那一行,再往后删除20行
sed -r '/2,5d' /etc/test # 第二行到第五行
sed -r '/root/d' /etc/test # 带root的行删除
sed -r '/root/!d' /etc/test # 除了root行以外都删除
sed -r '1~2d' /etc/test # 删除所有奇数行(从1开始,每隔两行删)
sed -r '0~2d' /etc/test # 删除所有偶数行
# 拓展:
vim中: 使用 `:r /etc/passwd` 来读取文件内容
|
命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 告诉sed对指定行进行何种操作
a 在当前行后添加一行或多行
c 用新文本修改(替换)当前行中的文本
d 删除行
i 在当前行前插入文本
l 列出非打印字符
p 打印行
n 读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理
q 结束或退出sed
! 取反(对所选行以外的所有行应用)
s 用一个字符串替换另一个
s 替换标志
g 在行内进行全局替换
i 忽略大小写
r 从文件中读
w 将行写入文件
y 将字符转换为另一个字符(不支持正则)
h 把模式空间里的内容复制到暂存缓冲区(覆盖)
H 把模式空间里的内容支架到暂存缓冲区中
g 取出暂存缓冲区中的内容,将其复制到模式空间,覆盖该处原有内容
G 取出暂存缓冲区中的内容,将其复制到模式空间,追加在原有内容后门
x 交换暂存缓冲区域模式空间的内容
|
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
## 例子
# d 删除
sed -r '3d' datefile # 删除第三行
sed -r '3d' datefile
sed -r '3{d;}' datefile
sed -r '3d{h:d}' datefile # 先保存,再删除
sed -r '3,$d' datefile # 删除3到最后一行
sed -r '$d' datefile # 删除最后一行
sed -r '/nrth/d' datefile # 删除满足这个匹配的行
# s 替换
sed -r 's/west/north/g' datefile
sed -r 's/^west/north/' datefile
sed -r 's[0-9][0-9]$/&.5' datefile # &代表在查找串中匹配到的内容 # 拓展vim中在某行的后门加上xxx: :3,5s/.*/&XXX/g
#vim拓展1: :%s/.*/#&/g 在所有行前面加注释
#vim拓展1: :3,5s/~/#&/ 和sed是一样的
sed -r '%s/(.)(.)(.*)/\1xxx\2\3/' passwd # 把每行第二个字符前面加xxx
sed -r 's/(Mar)got/\1inane/g' datefile
# r 读文件
sed -r 's/Suan/r /etc/newfile' datefile # 到Suan这一行的时候,读入一个新文件
sed -r '2r /etc/hosts' a.txt # 处理到第二行的时候,读入一个新文件
sed -r '/2r /etc/hosts' a.txt # /2 带有2的时候,读入...
# w 写文件
sed -r '/north/w newfile' datafile # 把north的行保存到新文件中去
sed -r '3,$w /new.txt' datafile # 第三行到最后一行,保存...
# a 追加
sed -r '/root/a 1111111' datafile # 有root的行,就在后面添加11111
sed -r '2a/ 1111111' datafile # 第二行,添加 111111111
# i 在前面插入
sed -r '/root/i 1111111' datafile # 有root的行,就在前面添加11111
sed -r '2i/ 1111111' datafile # 第二行,在前面添加 111111111
# c 修改替换
sed -r '2c/ 1111111' datafile # 第二行,替换为 111111111
# n 获取下一行命令
sed -r '/eastern/{n; d}' datafile # 这行没有明显标志,用上面明显的隔山打牛
# G g H h 暂存和取用命令
sed -r '1h;$G' /etc/hosts # 处理到第一行时候,暂存;到最后一行,取过来 (第一行复制到最后一行)
sed -r '1{h;d};$G' /etc/hosts # 第一行移动到最后一行
sed -r '1h;2,$G' /etc/hosts # 处理到第一行时候,暂存;到第二行和最后一行,取过来
|
模式空间/暂存空间
1
2
3
4
5
6
7
8
9
10
11
|
## 小写是覆盖,大写是追加
模式空间 h H --> 暂存空间
模式空间 <--- g G 暂存空间
sed -r 'G;G' /etc/hosts # 所有行
sed -r 'g;g' /etc/hosts
# 暂存空间个模式空间互相转换命令 x
sed -r '4h; 5x; 6G' /etc/hosts # 处理到第四行覆盖到暂存空间,到第五行:。。。
|
反向选择
1
2
|
sed -r '3d' /etc/hosts
sed -r '3!d' /etc/hosts
|
多重编辑选项
1
2
3
4
|
# -e
sed -r -e '1,3d' -e 's/java/python/' datafile # 第一行到第三行删除,后面的替换覆盖
sed -r '2{s/java/python/g; s/php/go/g}' datafile # 一行里面替换两次
|
常见操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
############ 常见操作
# 删除#注释行
sed -ri '/^#/d' file.conf # 这种情况必须是第一个就是注释符
sed -ri '/^[\t]*#/d' file.conf # 如果是前面有空格或tab然后才是注释符
# 删除//注释行
sed -ri '\Y/^[\t]*//Yd' file.conf
# 删除无内容空行
sed -ri '/^[\t]*$/d' file.conf
# 删除注释行及空行
sed -ri '/^[\t]*#|^[\t]*$/d' file.conf
sed -ri '/^[\t]*(#|$)/d' file.conf
# #加注释(vim是一样是)
:%s/.*/#&/g 在所有行前面加注释
:3,5s/^/#&/ 和sed是一样的
sed -r '1,5s/^/#/' c.txt
sed -r '3,$ s/^#*/#/' c.txt # 将行首0到多个井换成一个井
# 如果井前有空格或tab等
sed -r '3,$ s/^[\t]*#*/#/' c.txt
# sed使用外部变量(使用双引号)
var1=111
sed -ri "3a$val1" /etd/hosts
sed -ri '$a'"$val1" /etd/hosts # 第一个单引号是`最后一行`,第二个里面是变量
sed -ri "\$a$val1" /etd/hosts # 把$a转义一下也行
cat a.txt
tac a.txt # 从后往前倒序( sed -r '1!G; $!d' a.txt 推导一下弄明白 )
|
九.awk
awk本身也是一种编程语言(ps:我们使用的不是纯粹的awk,而是gawk)
语法格式
awk [options] 'cmd' filenames
options 选项
-F 指定分隔符,默认是空格或tab
command
1
2
3
4
5
6
7
8
9
|
# BEGIN{} 行处理前
# {} 行处理(有几行就处理几次)
# END 行处理后
awk 'BEGIN{print 1/2} {print "ok"}END{print "------"}' /etc/hosts
# BEGIN{} 通常用于定义一些变量,比如: BEGIN{FS=":";OFS="---"} # OFS 输出时候的字段分隔符
awk 'BEGIN{FS=":"} {print $1}' passwd # 在处理之前,(FS)就指定了分隔符
|
awk命令格式
1
2
3
4
5
6
7
8
9
10
11
12
|
# awk 'pattern' filename
awk '/root/' /etc/passwd
# awk '{action}' filename
awk -F: '{print $3}' /etc/passwd
# awk 'pattern {action}' filename
awk -F":" '/root/{print $3}' /etc/passwd
awk 'BEGIN{FS=":"} /root/{print $3}' /etc/passwd
# command |awk 'pattern {action}'
df -P |grep '/' |awk '$4'>25000 {print $4} # 除去第一行,如果大于25000就打印第四列
|
awk工作原理

记录与字段相关的内部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
## 可以通过 man awk 查看
# $0 awk变量保存当前记录的内容
awk -F":" '{print $0}' /etc/passwd
# NR 输入记录总的编号,显示行号
awk -F":" '{print NR,$0}' /etc/passwd
# FNR 当前记录文件的编号(处理多个文件,每个文件重新开始编号)
awk -F":" '{print FNR,$0}' /etc/passwd /etc/passwd
# NF: 保存记录的字段数(这一行一共有多少字段), $NF代表最后一个字段
awk -F":" '{print $0,NF,$NF}' /etc/passwd
# FS 输入字段分隔符,默认空格或tab
awk 'BEGIN{FS=":"} {print $0}' /etc/passwd
awk -F'[:\t]' '{print $0,NF,$NF}' /etc/passwd
# OFS 输入字段分隔符,默认空格, OFS:输出分隔符
awk 'BEGIN{FS=":";OFS="+++"} {print $0}' /etc/passwd
# RS --记录分隔符(区分与FS字段分隔符) 默认换行符
awk 'BEGIN{RS=":"} {print $0}' /etc/passwd
# ORS
awk 'BEGIN{ORS=":"} {print $0}' /etc/passwd
# 将文件每一行合并为一行(ORS 输出记录分隔符)
awk 'BEGIN{ORS=""} {print $0}' /etc/passwd
|
格式化输出
1
2
3
4
5
6
|
# 1.print
# 2.printf 可以格式化(默认没有换行,手动加\n)
date |awk '{print "Month:" $2"\nYear: " $NF}' # 只要不是变量,就要放到双引号里面
# %s 字符串(-15s 15个字符,左对齐) %f 浮点型, %d数值类型
awk -F: '{printf "%-15s %-10s %-15s\n", $1,$2,$3}' /etc/passwd
|
awk模式和动作
模式:条件语句,复合语句,正则表达式。 包括两个特殊字典:BEGIN和END
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
### 模式可以是
======= 正则表达式
# 匹配记录(整行)
awk '/^xps/' /etc/passwd # awk '$0 ~ /^xps/' /etc/passwd # ~ 匹配
awk '!/xps/' /etc/passwd # awk '$0 !~ /^xps/' /etc/passwd
# 匹配字段:匹配操作符(~!~)
awk -F: '$1 ~ /^xps/' /etc/passwd #
awk -F: '$NF !~ /^bash$/' /etc/passwd # 最后一列不是以bash结尾的
======= 比较表达式
# 用于比较 数字 与 字符串
# > < ==
awk -F: '$3 == 0' /etc/passwd
awk -F: '$3 == "/xps/"' /etc/passwd # == 全部等于
awk -F: '$3 ~ /xps/' /etc/passwd # 正则匹配
awk -F: '$NF ~ /xps/' /etc/passwd
======= 条件表达式
awk -F: '$3>200{print $0}' /etc/passwd # $3大于200的,$0
awk -F: '{ if($3>200) {print $0} }' /etc/passwd # 推荐这么写 { if(){cmd1;cmd2} else{} }
awk -F: '{ if($3>200) {print $0} else{print $1} }' /etc/passwd
======= 算数运算
#awk都按浮点数方式执行算数运算
awk -F: '$3 * 10 > 500' /etc/passwd
awk -F: '{ if($3*10>500){print $0} }' /etc/passwd # 如果$3*10>500,就...
======= 逻辑操作符和复合模式
&& 逻辑与
|| 逻辑或
! 逻辑非
awk -F: '$1~/root/ && $3<=15' /etc/passwd
awk -F: '$1~/root/ || $3<=15' /etc/passwd
awk -F: '!($1~/root/ && $3<=15)' /etc/passwd
======= 范围模式
awk '/Tom,/Susan/' filename
|
awk脚本编程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
### awk脚本编程
====== 条件编程
awk -F":" '{if(){} else if(){} else{}}' passwd
awk -F":" '{if($3>0 && $3<1000){count++}} END{print count}' /etc/passwd # 统计系统用户数
awk -F":" '{if($3==0){count++}} else{i++} END{print "管理员个数:"count; print "系统用户个数:"i}' /etc/passwd
awk -F":" '{if($3==0){i++}} else if($3<999){j++} else{k++} END{print "管理员个数:"i; print "普通用户个数:"j; print "系统用户个数:"k}' /etc/passwd
====== 循环
# 1.while 依此打印每一列
awk -F":" '{i=1;while(i<7){print $i;i++}}' /etc/passwd
awk -F":" '/^root/{i=1;while(i<7){print $i;i++}}' /etc/passwd
awk -F":" '{i=1;while(i<=NF){print $i;i++}}' /etc/passwd
awk '{i=1;while(i<=NF){print $i;i++}}' a.txt # 打印文件所有内容(默认是空格和tab分割)
# 2.for
awk 'BEGIN{for(i=1;i<=5;i++){prin i}}' # c风格的
awk -F: '{for(i=1;i<=NF;i++){prin $i}}' passwd
awk -F: '{for(i=1;i<=NF;i++){prin $0}}' passwd # 将每行打印10次
====== 数组 (用来统计)
awk -F: '{username[++i]=$1} END{print username[1]}' /etc/passwd
awk -F: '{username[i++]=$1} END{print username[1]}' /etc/passwd
awk -F: '{username[i++]=$1} END{print username[0]}' /etc/passwd
## 数组遍历(主要用按索引遍历)
# username数组名, 先保存到数组中,再进行遍历
awk -F: '{username[i++]=$1} END{for(i in username) {print i,username[i]}}' /etc/passwd
awk -F: '{username[++i]=$1} END{for(i in username) {print i,username[i]}}' /etc/passwd
|
基本练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
###### 基本练习
### 1. 统计/etc/passwd 中各种shell的数量
# # 把要统计的对象作为数组的索引(这里是最后一个$NF,也就是shell的类型)
awk -F: '{shells[$NF]++} END{for(i in shells){print i,shells[i]}}' /etc/passwd
### 2.网站访问状态统计
netstat -ant |grep :80 |awk '{access_stat[$NF]++} END{for(i in access_stat){print i,access_stat[i]}}'
netstat -ant |grep :80 |awk '{access_stat[$NF]++} END{for(i in access_stat){print i,access_stat[i]}}' |sort -k2 -n |head
ss -ant |grep :80 |awk '{access_stat[$2]++} END{for(i in access_stat){print i,access_stat[i]}}'
### 3.统计当前访问的每个IP的数量 <当前实时状态 netstat, ss>
netstat -ant |grep :80 |awk -F: '{ip_count[$8]++} END{for(i in ip_count){print i,ip_count[i]}}'
# 下面这个有点复杂了,不推荐用
ss -ant |grep :80 |awk -F: '!/LISTEN/{ip_count[$(NF-1)]++} END{for(i in ip_count){print i,ip_count[i]}}' |sort 0k2 -rn |head 5
### 4.统计Apache/Nginx日志中某一天的PV量 <统计日志>
grep '07/Aug/2019' access.log |wc -l # wc -l 统计行数
### 4.统计Apache/Nginx日志中某一天不通IP的PV量 <统计日志>
grep '07/Aug/2019' access.log |awk '{ips[$1]++} END{for(i in ips){print i, ips[i]}}' |sort -k2 -rn | head
awk '/22/\Mar\/2019/{ips[$1]++} END{for(i in ips){print i, ips[i]}}'
# >100的才打印(此方法有点low,可用下面的几种方法)
awk '/22/\Mar\/2019/{ips[$1]++} END{for(i in ips){print i, ips[i]}}' | awk '$2>100' |sort -k2 -rn | head
awk '/22/\Mar\/2019/{ips[$1]++} END{for(i in ips){if(ips[i]>100){print i, ips[i]}}}' |
# >100的才打印
awk '$2>100' |sort -k2 -rn | head
#【思路】 将要统计的字段作为数组的索引
### awk函数
# 统计用户名为4个字符的用户
awk -F: '$1~/^....$/{count++;print $1} END{print "count is:" count}' /etc/passwd
# length
awk -F: 'length($1)==4{count++;print $1} END{print "count is:" count}' /etc/passwd
### awk自定义变量(外部变量)
# 1.再双引号里面
var=bash
echo "unix script" |awk "gsub(/unix/, \"$var\")" # 转义双引号,里面是$变量
# 2.两个双引号里面套个单引号
echo "unix script" |awk 'gsub(/unix/, "'"$var\"'")'
#
df -h |awk '{ if(int($5)>10){print $6":"$5} }'
# 再函数外面单引号情况下
i=10
df -h |awk '{ if(int($5)>'''$i'''){print $6":"$5} }'
# 3.建议: -v
awk -v user=root -F:'$1 == user' /etc/passwd # 在-v的时候定义变量user=root
var=bash
echo "unix script" |awk "gsub(/unix/, var)"
# 前面造一条命令,传给bash执行
arp -n |awk '/^[0-9]/{print "arp -d $1"}' |bash
|
实例
实践中再写…..
附
其他参考文章:
https://blog.csdn.net/u011436427/article/details/103815680
https://mp.weixin.qq.com/s/dXLlFgQS_3KHm8YRyDC7ZQ